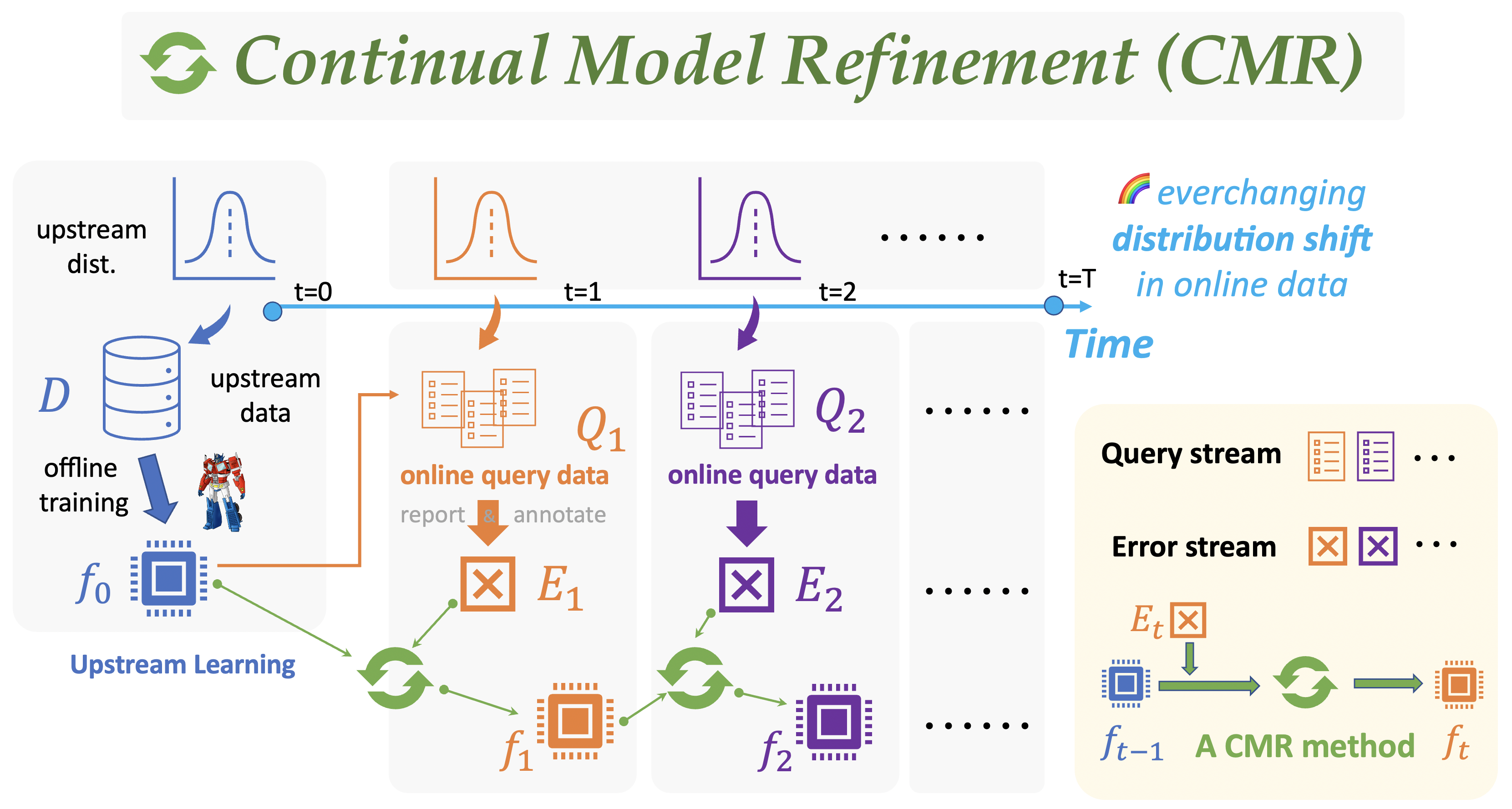
The Benchmark Data for CMR
Table of contents
- Download and Preprocess
- Generating OOD data streams
- More configurations for generating OOD data streams
Download and Preprocess
Here we use the MRQA datasets as an example to show how datasets should be processed.
- download the data files
cd data/mrqa/ bash download.sh - preprocess the datasets
cd ~/CMR/ # go to the root folder of CMR project, say ~/CMR/ python data/data_formatter.py
After thest two steps, you should see a few mrqa_* folders under the data folder, where each is for a particular data cluster.
Generating OOD data streams
Generate upstream model predictions.
We first use the upstream model to infer examples from other data clusters.
mkdir -p upstream_resources/qa_upstream_preds/tmp/ # under the CMR folder
bash scripts/run_mrqa_infer.sh
The first part of this script is to test the upstream model on the upstream training data, and the second part is to test the upstream model on other data clusters’ dev data.
Sample data streams.
Now we generate the data streams and evaluation sets that we need for our experiments. The default configurations that are used here can be found in the code file.
mkdir -p experiments/eval_data/qa/
python cmr/benchmark_gen/sample_submission_streams.py --task_name QA
The generated data streams can be visualized by running cmr/benchmark_gen/visualize_streams.py.
More configurations for generating OOD data streams
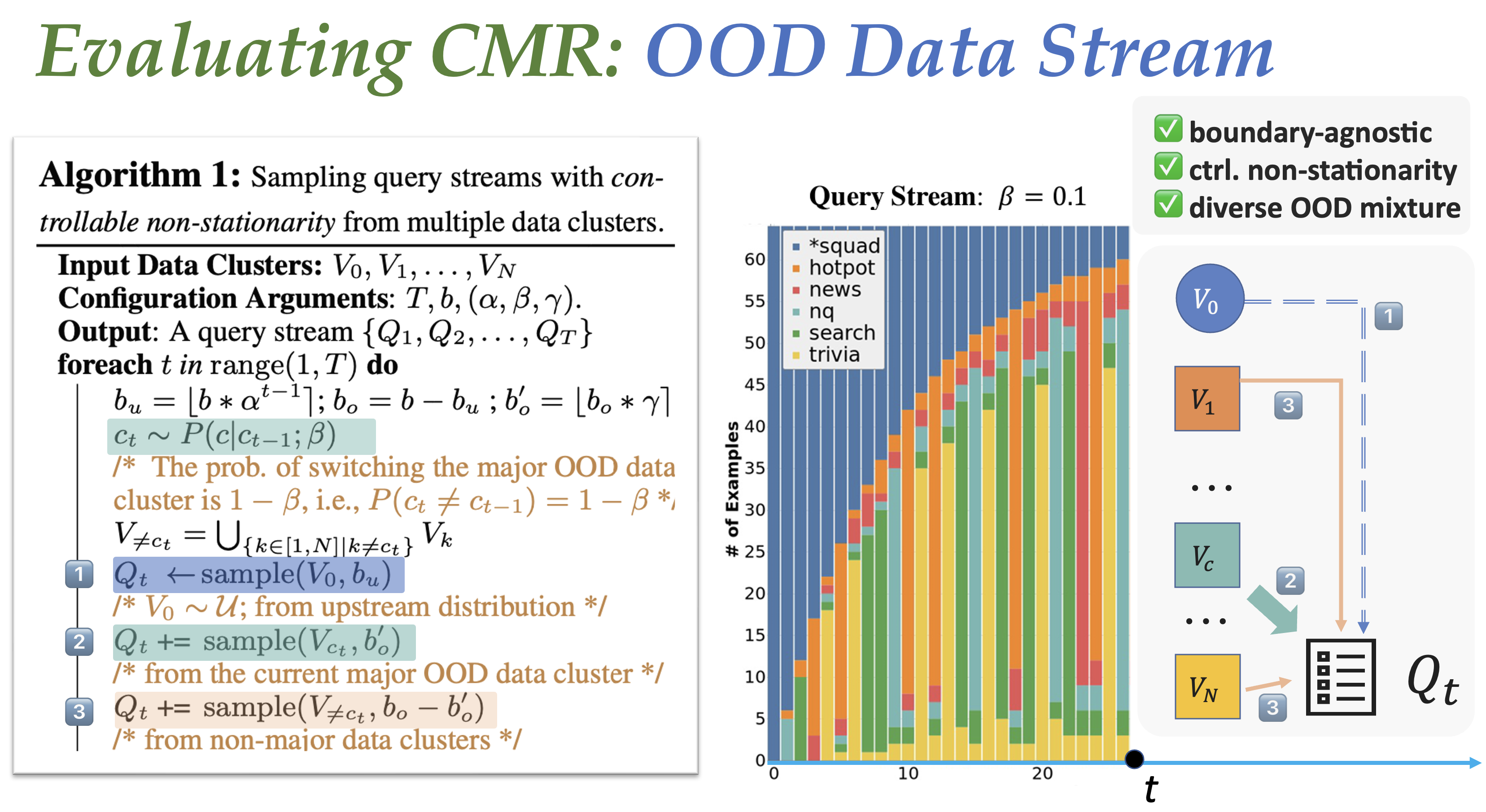
TODO: here, we will introduce the details for using the sample_submission_streams.py for generating the OOD data streams as described in the above picture.